

Ten architectural patterns. Four responsibility layers. A cluster of papers surfacing in the same news cycle. That's not coincidence. That's convergence.
On June 23, 2026, the AI agent field stopped iterating on prompts and started replacing the monolithic agent with something modular, mediated, and actually governable. The signal wasn't one paper. It was a stack of them, plus two product launches from companies that do not typically agree on anything.
IBM Research shipped CUGA, a lightweight agent harness with two dozen working examples. NVIDIA launched its Agent Toolkit, bundling open models, skill tooling, and a secure runtime. And behind both announcements sat a reference architecture that finally gives builders a vocabulary for what has been going wrong.
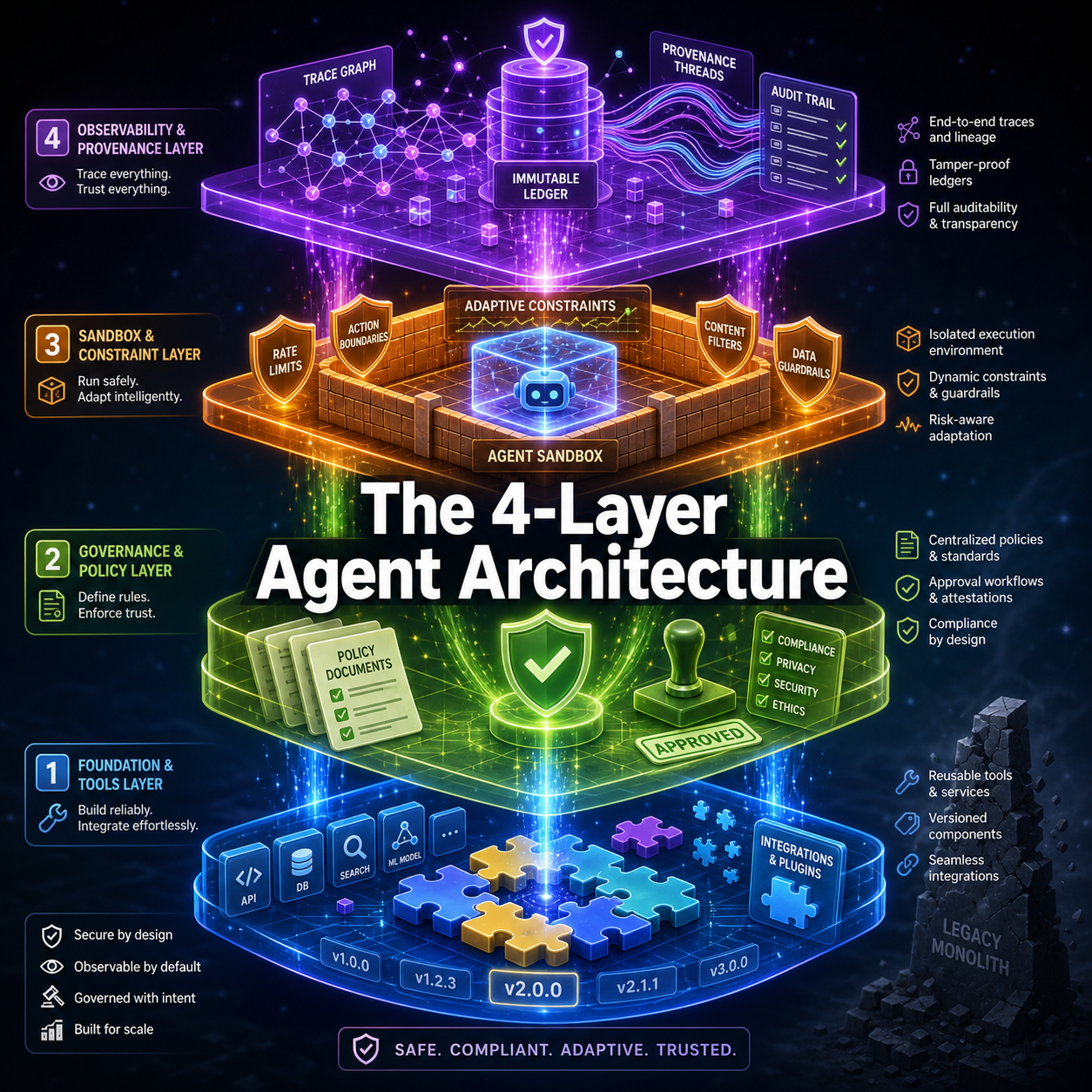
The Harnessing Agent Skills paper, by Xia et al., catalogues ten empirically grounded architectural patterns across eight existing agent systems. Five core patterns. Five supporting patterns. Synthesized into four responsibility layers that every production agent framework needs, whether it admits it or not.
Most production agents today are monolithic black boxes. One model. One context window. One failure mode that takes down the entire system. We have covered this before. Agent paralysis happens when your agent cannot decide which tool to use. Tool attention failures happen when it picks the wrong one. Both symptoms point to the same disease: the agent was never designed as a system. It was designed as a loop.
The four-layer architecture is the treatment.
The Four Layers Explained
Supply Chain Layer
This is where skills are built, versioned, tested, and published. It is package management for agent behavior. Without it, you are copying and pasting function definitions and calling them skills.
IBM's CUGA gets this right. It is a harness, not a framework. You bring your own model, your own tools, your own prompts. CUGA handles the orchestration, the execution loop, and the state plumbing. The result is two dozen single-file apps, each a working FastAPI route wrapping one agent. Real agentic workflows, not toy demos.
IBM Research branding matters here. This is not a side project from a research intern. It is a deliberate signal that enterprise agent infrastructure needs to be modular, composable, and mix-and-match. CUGA is pip-installable and production-governed without a rewrite.
Mediation Layer
This is where policy meets code. The Mediation layer binds skills to context and authority constraints before execution ever starts. It answers questions like: does this agent have permission to run this skill? Does this skill apply to this environment? Who approved it?
The Specifying AI-SDLC Processes paper, by Prifti, proposes a domain-specific language for exactly this. It formalizes the "2+N team pattern": two human-in-control roles plus N specialized agent members. Structural enforcement bounds system failure rates at a weighted product of agent and validator rates. Behavioral compliance permits cumulative growth. In plain English: if you let agents self-police, failure compounds. If you enforce boundaries structurally, failure multiplies but stays bounded.
This is Separation of Duties for the AI age. And most agent frameworks do not have it.
Execution Control Layer
This is where skills are interpreted at runtime with safety boundaries. The Execution Control layer is what keeps your agent from deleting a production database because it misread a prompt.
SkillHarness, by Chen et al., addresses the safety gap that has blocked computer-use agents in production. Existing skill learning methods assume static, safe environments. They overlook prompt injections, pop-ups, and adversarial interactions. SkillHarness introduces "skill boundaries" that leverage multi-source supervision signals to identify safe skills from interaction trajectories. It then constructs self-improving safety constraints that adapt as the agent encounters new environments.
The results are concrete. SkillHarness reduced the unsafe rate of learned skills by 57.1 percent. It improved execution stability under dynamic environmental changes. That is not a marginal gain. That is the difference between a demo and a deployment.
Evidence & Feedback Layer
This is the layer most builders skip. It captures run evidence for attribution, verification, repair, and evolution. Without it, governance is theater.
Agent-runtime systems already emit traces, ledgers, provenance graphs, policy logs, delegation tokens, cache events, and tool-firewall records. But DEMM-Bench, by Solozobov, asks the question nobody has answered: what constitutes sufficient governance evidence?
DEMM-Bench is a cross-regime benchmark covering financial regulation, healthcare compliance, and defense-grade security. It found that trace-present and schema-present baselines overclaim on 75 percent of cases. Ledger-present baselines overclaim on 50 percent. Most agent runtimes think they are producing evidence. They are producing noise.
If your agent makes a bad call and you cannot reconstruct why, you do not have governance. You have logging. Those are different things.
Each layer has a job. If your agent framework does not have all four, you have a hole.
Why This Matters for Production
The architecture is not abstract. It maps directly to problems PhantomByte readers are already fighting.
Safety
SkillHarness proves that static skill abstractions fail in dynamic environments. The 57.1 percent reduction in unsafe rates is not a benchmark optimization. It is a barrier removal. Computer-use agents have been stuck in research demos because nobody could guarantee they would not break things in the real world. Skill boundaries change that.
Self-improving safety constraints mean the agent gets safer as it encounters more environments. This is the opposite of most safety approaches, which hardcode rules and degrade over time.
Multi-Agent Reliability
PEAR, by Feng et al., fixes a problem most multi-agent systems pretend does not exist: positional bias.
Fixed topologies amplify unreliable agents by giving them permanent, privileged positions. If Agent A always speaks first and Agent B always critiques, the system's accuracy depends heavily on whether Agent A got lucky that day. PEAR introduces permutation-equivariant adaptive routing, which dynamically reconfigures communication roles and sparse topologies across debate rounds. No agent permanently occupies a privileged network position.
Evaluated across four reasoning benchmarks and six diverse LLM backbones, PEAR significantly improved average accuracy over the strongest debate baselines. The code is public. The problem it solves is real.
Attribution
When an agent makes a bad call, who is responsible? The Evidence & Feedback layer answers that with traces, ledgers, provenance graphs, and delegation tokens. Without it, you cannot audit, you cannot comply, and you cannot repair.
DEMM-Bench found that current runtimes overclaim on evidence sufficiency in the majority of cases. If you are building agents for regulated industries, that is not a footnote. That is a liability.
The Implementation Gap
Be skeptical. Not every paper ships. Not every framework works.
CUGA is IBM Research branded, which gives it enterprise credibility. But it is new. Two dozen examples is a strong start, not a mature ecosystem. The Hugging Face blog post is dated June 23, 2026. We are writing this on June 24, 2026, just one day after the launch. If you are reading this a year from now, check whether CUGA has community traction or became another abandoned research artifact.
NVIDIA's Agent Toolkit is a platform play from a hardware company. It bundles Nemotron open models, NeMoClaw blueprints for safer agent behavior, and an OpenShell runtime. The blog post explicitly mentions compatibility with third-party harnesses including Hermes Agents and OpenClaw. That openness is unusual for NVIDIA. It is also strategic. They are not selling you an agent framework. They are selling you the infrastructure underneath it.
Most of these papers are position papers or frameworks without empirical benchmarks on real workloads. The AI-SDLC paper notes that "empirical evaluation is future work." The Harnessing Agent Skills architecture was evaluated through cross-instantiation across eight systems, not through controlled experiments. The 4-layer architecture is a vocabulary, not a library you can pip install.
Reference architectures are easy. Reference implementations are hard.
What a builder can do today:
- Audit your current agent framework against the 4 layers. Which ones are missing?
- Start versioning your tools as skills with explicit boundaries, not just function definitions.
- Implement run logging that captures provenance, not just console output.
- Separate skill discovery from skill execution. Mediation is not execution.
The Uncomfortable Question
If your agent framework is still one model, one prompt, one while loop, you are not building the next generation. You are maintaining the last one.
How many of the 4 layers does your agent actually have?
Get More Articles Like This
Getting your AI agent setup right is just the start. I'm documenting every mistake, fix, and lesson learned as I build PhantomByte.
Subscribe to receive updates when we publish new content. No spam, just real lessons from the trenches.
Build Real AI Infrastructure
PhantomByte teaches you to build real AI infrastructure yourself: local AI stacks, autonomous agents, multi-agent orchestration, web scraping, and custom tools. Step-by-step PDF tutorials you download, follow, and deploy. No subscriptions. No fluff. Just skills that ship.