
Every frontier lab is training on synthetic data. OpenAI, Anthropic, Google DeepMind, and every startup pitching a data flywheel assumes the same safeguard. Use a verifier to select the best synthetic samples. Throw out the garbage. Keep the gold. An ICML 2026 paper proves this assumption is wrong. When the verifier sees only a fragmented slice of reality, selection does not prevent model collapse. It accelerates it. The safeguard is the poison.
This is not a theoretical worry. It is a theorem, with authors, equations, and a conference acceptance letter. Xinbao Qiao, Xianglong Du, Wei Liu, and colleagues submitted arXiv:2606.13732 on June 11, 2026. The International Conference on Machine Learning accepted it for its 43rd meeting. The paper's title is blunt: "When Sample Selection Bias Precipitates Model Collapse." The abstract is blunter. Data selection, widely viewed as a remedy against model collapse, can instead become the mechanism that causes it when the verifier's reference distribution is incomplete. The paper proves this mathematically and demonstrates it empirically.
If you run a training pipeline that generates synthetic data and filters it through a quality verifier, you need to understand what happens when that verifier is blind to part of the world. Because blind is the default state in every siloed domain.
The Scarcity Paradox
Synthetic data was supposed to solve data scarcity. The logic is seductive. Real data is expensive, private, and finite. Synthetic data is cheap, unlimited, and generated on demand. Models training on model outputs is now standard practice at every frontier lab and hundreds of startups. The playbook is identical across the industry: generate infinite synthetic samples, filter them through a quality verifier, train the next generation on the winners, repeat.
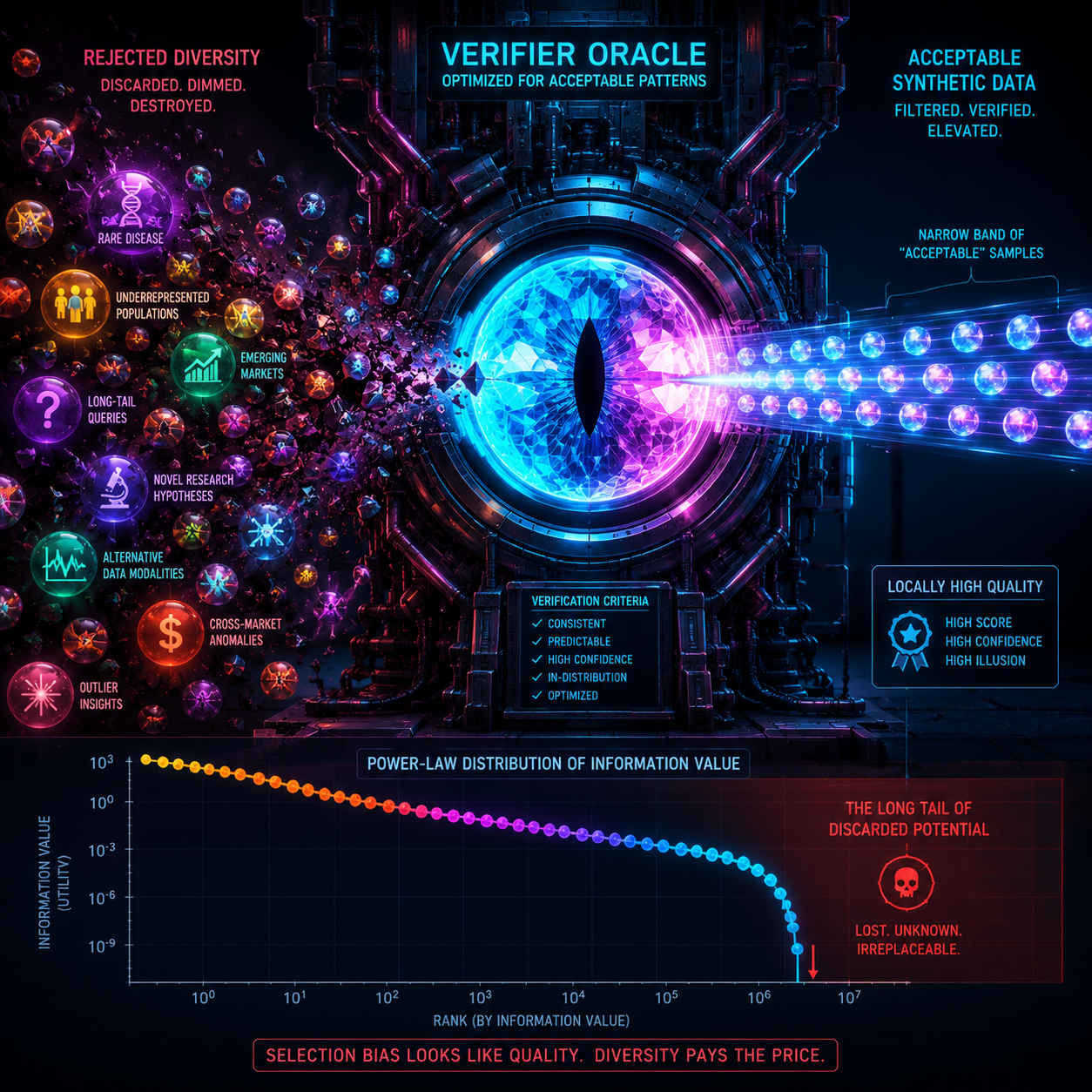
The verifier sits at the center of this loop. It is treated as a firewall against degeneration. Its job is to reject low-quality synthetic samples and preserve the ones that resemble real data. The assumption is that a well-trained verifier can distinguish good synthetic data from bad, ensuring that only high-fidelity samples enter the training set. If the synthetic data drifts, the verifier catches it. If the model starts generating nonsense, the verifier filters it out. The verifier is supposed to be the immune system of the training pipeline.
The ICML 2026 paper calls this assumption into question with a theorem and an empirical demonstration. The authors show that verifiers with incomplete reference distributions do not protect against collapse. They turn selection into a diversity shredder. The mechanism is sample selection bias, and it is not an edge case. It is the default in every siloed environment.
The Mechanism: Sample Selection Bias
The paper defines sample selection bias as the condition where each verifier in a pipeline observes only a small, fragmented slice of the target distribution. This is not a rare failure mode. It is the standard operating condition in any domain where raw data cannot be freely pooled across institutions.
Healthcare consortia cannot pool raw patient data across institutions because of HIPAA, GDPR, and institutional review board restrictions. Each hospital builds its own verifier on its own patient population. Banks cannot merge transaction records across borders because of financial secrecy laws and regulatory compartmentalization. Each jurisdiction trains its own verifier on its own transaction history. Government agencies run on compartmentalized datasets where classification levels, jurisdictional boundaries, and political sensitivities prevent data sharing. Each agency builds its own verifier on its own slice.
The theoretical result is sharp. The authors prove that siloed, biased selection accelerates model collapse. It induces a power-law decay in diversity. This is a distinct failure mode from standard recursive training collapse, where a model trained on its own outputs gradually homogenizes. It is also distinct from pure data scarcity, where there is simply not enough real data to begin with. This is something worse: the presence of a selection mechanism that actively destroys the diversity the pipeline needs to survive.
Here is how it works. The verifier judges quality against its partial reference. Samples that look excellent to the verifier may still lack global diversity, but the verifier has no way to know that. A synthetic medical case that reflects a rare disease presentation might look wrong to a verifier trained on a geriatric population. A synthetic financial scenario reflecting Asian market dynamics might look anomalous to a verifier trained on US equities. The verifier rejects these samples not because they are bad, but because they are unfamiliar. Over successive generations, the selected data drifts toward the verifier's bias. Underrepresented cases vanish. The distribution narrows. And because the verifier is supposed to be the safeguard, the collapse is invisible until it is catastrophic.
The paper's empirical results confirm this. Local-reference selection fails systematically on skewed distributions. The verifier becomes a reinforcing loop for its own blind spots.
The Healthcare and Finance Examples
Imagine three hospitals training a medical AI. Each hospital has a verifier trained on its own patient population. Hospital A serves mostly elderly patients in an urban setting. Its verifier selects synthetic cases that look like its data: chronic conditions, polypharmacy, age-related presentations. Hospital B serves mostly pediatric patients in a suburban setting. Its verifier does the same: developmental disorders, infectious diseases, pediatric dosing patterns. Hospital C serves a mixed population but with a specialty focus on oncology.
Neither verifier is wrong locally. All three are wrong globally. The pooled synthetic dataset selected by these fragmented verifiers overweights common demographics and eliminates rare disease presentations. A synthetic case of cardiac amyloidosis in a young adult looks wrong to all three verifiers. A synthetic case of pediatric autoimmune encephalitis might pass Hospital B but be altered or rejected by Hospitals A and C because their verifiers flag it as statistically anomalous. The resulting model collapses toward the average case and forgets the edge cases where accuracy matters most.
In medicine, edge cases are not edges. They are the patients who die when the model misdiagnoses them because it has never seen their presentation before. The verifier did its job. It selected high-quality samples according to its reference. The reference was just too narrow to save a life.
Finance is identical. A verifier trained on US equities discards synthetic scenarios that reflect Asian market dynamics because they look like outliers. A verifier trained on consumer credit rejects synthetic small-business patterns because they do not match the risk profiles in the training data. A verifier trained on European banking regulations filters out synthetic cases reflecting emerging-market compliance gaps. The selected data converges on the verifier's home market. The model loses the heterogeneity that makes it robust.
When a global financial shock hits, the model that has trained only on locally typical scenarios fails on the globally atypical ones. The 2008 financial crisis was a story of models that assumed US housing data was representative of the world. The synthetic data pipeline with siloed verifiers rebuilds that assumption into the training loop itself.
The Mitigation: Wasserstein Proxy References
The paper proposes a concrete fix. Construct Wasserstein proxy references from multiple silos without sharing raw data. The Wasserstein distance is a measure of distributional difference that operates on probability distributions, not on individual data points. Each institution contributes a proxy distribution, not the underlying records. These proxies approximate the full population distribution. The verifier selects against the combined proxy, not its own local slice.
Empirically, this preserves diversity where local-reference selection fails. The paper's experiments show that collaborative proxy references mitigate diversity degradation compared to siloed selection. The verifier still makes selections, but it makes them against a reference that approximates the global distribution rather than the local one.
The cost is coordination. Institutions must agree on proxy representation formats, update schedules, and trust frameworks. The proxies themselves must be constructed carefully to avoid leaking sensitive information about the raw data. Differential privacy techniques may be necessary to ensure that the proxy distributions do not reveal individual records. The engineering overhead is real.
The benefit is preventing a training pipeline from teaching the model that the world is narrower than it is. For a healthcare consortium, that means rare diseases stay in the training distribution. For a global bank, that means cross-market correlations stay represented. For any organization running synthetic data pipelines, that means the verifier stops being an accelerant for collapse and starts being the safeguard it was supposed to be.
The Alternative Path: Self-Play Evolution
Hybrid Open-Ended Tri-Evolution, from arXiv:2606.13710, offers a completely different approach to generating training signal without the verifier trap. Instead of filtering synthetic data through an external verifier that might be biased by its reference distribution, HOTE uses three co-evolving modules that generate and evaluate training signal internally.
The proposer generates challenging queries. The solver produces long-form research reports by autonomously planning, searching, and citing sources. The judge evaluates solver responses without requiring verifiable ground-truth answers. Instead, the judge dynamically produces rubrics to assess quality, and the proposer uses web-scale knowledge seeking to generate queries that expose solver weaknesses.
The modules train each other through hybrid-mode reinforcement learning. Half of each training batch uses tool-assisted search. Half uses purely parametric reasoning. This dual-mode approach achieves mutual benefit between modes: the tool-use half grounds the model in retrievable facts, while the parametric half forces the model to develop internal reasoning capabilities that do not depend on external search.
On three long-form deep research benchmarks, HealthBench, ResearchQA, and DeepResearchBench, an 8B model trained with HOTE surpasses all open-source 8B to 32B models as well as state-of-the-art deep research training methods including SPICE, Dr. Zero, GRPO, GSPO, and REINFORCE++, with less time overhead.
This is not a drop-in replacement for every pipeline. HOTE is designed for deep research and reasoning tasks where the training signal can be generated through internal evaluation rather than external verification. But for those domains, it eliminates the verifier entirely. There is no external reference distribution to be biased. The model evolves its own training curriculum through self-play.
The philosophical difference is worth noting. Wasserstein proxies try to fix the verifier by making its reference more complete. HOTE removes the verifier from the loop entirely and replaces it with an internal evolutionary process. Both approaches recognize that the standard pipeline is broken. They just fix it differently.
What This Means for the IPO Class of 2026
SpaceX went public in the largest IPO in history. OpenAI and Anthropic have filed confidentially. The summer of 2026 is the AI IPO season, and every prospectus touts proprietary training infrastructure and data advantages. None of them disclose the fragility of their synthetic data verifiers. None of them mention sample selection bias, power-law diversity decay, or Wasserstein proxies.
This is not a conspiracy. It is an omission. Public companies are not required to disclose the mathematical properties of their training pipelines in prospectus language. But the omission matters for technical investors who are trying to price these companies accurately. If your verifier is trained on a fraction of the world, your model learns that fraction squared. The training pipeline is rotting from the inside, and the quarterly reports will not tell you until it shows up in benchmark regression.
The MANGOS acronym, coined by TechCrunch's Equity podcast in June 2026, replaces FAANG with Meta, Anthropic, Nvidia, Google, OpenAI, and SpaceX. It reflects a market that is pricing AI infrastructure as the dominant sector of the next decade. But infrastructure is only valuable if it works. A training pipeline that collapses diversity through biased selection is infrastructure that degrades its own product with every generation.
For investors, the due diligence question is not whether a company uses synthetic data. Everyone does. The question is whether the company recognizes that its verifier might be the weakest link in its entire stack. A company that has implemented Wasserstein proxies or alternative verification architectures has thought through this problem. A company that treats its verifier as a solved problem has not.
The market will not price this risk until the regressions become public. By then, the models will have been trained, deployed, and integrated into customer workflows. The correction will be costly.
The Real Cost of Cheap Data
Synthetic data is free until you pay for it in collapsed capability. The model that forgets rare diseases does not announce its ignorance. It simply performs worse on the cases that matter most. The model that loses cross-market financial patterns does not flash a warning light. It just fails when the correlation structure changes.
Fixing this with Wasserstein proxies or HOTE self-play costs engineering time and coordination overhead. It requires institutions to share proxy distributions, agree on formats, and maintain update schedules. It requires research teams to rethink whether an external verifier is even the right architecture for their domain. These costs are upfront and visible.
Not fixing it costs accuracy in the tail. For a medical AI, the tail is the patient with the rare presentation who gets misdiagnosed because the model has never seen her case. For a financial AI, the tail is the market dislocation that happens in the segment the verifier filtered out. For a public company selling frontier models, the tail is where liability lives.
The narrative around synthetic data has been dominated by abundance. Infinite samples, infinite variety, infinite scaling. The ICML 2026 paper reframes the narrative around scarcity: not scarcity of data, but scarcity of diversity preserved through the selection process. The verifier does not add diversity. It can only preserve what it already sees. When what it sees is incomplete, what it preserves is incomplete too.
The Uncomfortable Question
If your training pipeline treats the verifier as a firewall against collapse, and the verifier is actually an accelerant, what percentage of your model's capability is diversity you already lost three generations ago?
This is not rhetorical. It is a quantitative question that most organizations cannot answer because they do not track the diversity of their synthetic training distributions over time. They track loss curves and benchmark scores. Those metrics can improve while the underlying distribution collapses, because benchmarks are designed to measure average-case performance, not tail coverage.
The verifier that rejects rare cases improves benchmark scores on common cases. The model looks better on paper while becoming less useful in reality. Three generations of selection bias compound exponentially. A verifier that misses 10% of the distribution in generation one leaves a progressively smaller residue of that 10% in each subsequent generation. By generation three, the missing modes are not just underrepresented. They are gone.
Organizations running synthetic data pipelines should audit their training distributions for diversity decay. They should measure whether the tail of the synthetic distribution is thinning relative to the real distribution. They should treat verifier reference completeness as a first-class engineering concern, not a data preprocessing afterthought.
Most do not. Most treat the verifier as a solved problem, a checkbox in the training pipeline that says "quality control complete." The paper proves that this checkbox is where the collapse begins.
Close
You cannot verify what you cannot see. Build the proxy, or inherit the blind spot.
The ICML 2026 paper gives you the mathematics to understand why your verifier might be destroying the diversity your model needs. The Wasserstein proxy gives you a way to fix it without surrendering data sovereignty. HOTE gives you a way to bypass the verifier entirely. The tools exist. The question is whether you use them before the decay becomes irreversible.
Every frontier lab is training on synthetic data. The ones that survive the next five years will be the ones that realized the safeguard was the poison, and changed the pipeline before the collapse became visible in the quarterly report.
Get More Articles Like This
Getting your AI agent setup right is just the start. I'm documenting every mistake, fix, and lesson learned as I build PhantomByte.
Subscribe to receive updates when we publish new content. No spam, just real lessons from the trenches.