
Your AI agent remembers everything you told it last week. That is the pitch. The reality is that persistent agent memory is a consistency nightmare dressed up as a feature.
A new paper called MemTrace proves that aggregate accuracy scores miss the critical failure modes. Stale facts. Contradictory beliefs. Hallucinations that propagate across sessions like a virus. OpenAI's upgraded ChatGPT memory is actively making answers worse by injecting outdated personal assumptions into responses nobody asked for. Every agent framework, LangGraph, CrewAI, AutoGen, handles memory differently. They are all broken, just in different ways.
This is the hardest engineering problem in agent infrastructure, and nobody has solved it.
The Aggregate Accuracy Trap
MemTrace, published on arXiv by Xianxuan Long and colleagues at Michigan State University, approaches memory evaluation differently than any previous benchmark. Instead of scoring question rows independently, MemTrace treats the knowledge point, a single typed fact about the user, as the unit of measurement. It then probes each fact along three controlled dimensions: memory age (how many sessions ago the fact appeared), question type (current state, earlier state, or trajectory of change), and evidence condition (present, missing, or contradicted by a false premise).
The results expose a brutal gap between what benchmarks claim and what actually happens in production. The authors evaluated thirteen memory-system configurations across four paradigms and found that similar pooled accuracy hides radically different failures. A system can recover a fact's current state and its earlier state and still fail to track how it changed. Safe abstention, the polite "I don't know" that benchmark evaluators love, does not imply that the system will correct a false premise when presented with contradicting evidence.
Here is the finding that should terrify anyone shipping a production agent: the dominant bottleneck is evidence use, not retrieval. When memory systems fail, the evidence was retrievable ten times more often than it was actually missing. The memory had the data. It just did not know what to do with it. That is not a storage problem. That is a reasoning problem, and it gets worse the longer your agent runs.
Think about what this means in practice. A customer support agent that gives wrong answers 5% of the time across 1,000 sessions is not a 95% success story. It is a disaster with compounding interest. Every wrong answer becomes input for the next session. Every stale fact becomes a permanent bias. Every hallucinated detail gets filed alongside real data with no distinguishing mark. Aggregate accuracy treats each session as an independent trial. Agent memory does not work that way. It is a stateful system with feedback loops, and feedback loops amplify error.
ChatGPT's Memory Downgrade in Practice
If you want to see what happens when a consumer product ships persistent memory without consistency safeguards, look at ChatGPT's recent upgrade.
Tests from ZDNet, documented in the TensorFeed daily report for June 18, 2026, reveal that ChatGPT's expanded memory feature builds comprehensive user profiles from past chats. It goes far beyond a simple list of facts. It now incorporates entire chat histories, explicit instructions, personal constraints, and implicit preferences the model derives from casual remarks. The result is a profile that feels personalized and acts like a loaded weapon.
The testers found outdated assumptions persisting across conversations. Incorrect personal details becoming permanent fixtures. Implicit preferences derived from offhand comments distorting unrelated future answers. You mention in passing that you prefer short emails, and three weeks later ChatGPT is compressing technical explanations into bullet fragments. You correct a biographical detail once, and the old version still surfaces in tangential responses because the memory layer never reconciled the conflict.
The most disturbing finding: turning memory off does not fully erase what the system already learned about you. The profile persists. The derived preferences linger. The damage is done before you realize there is a setting to disable. This is not a privacy issue alone. It is a consistency issue. A memory system without expiration, without contradiction detection, and without quarantine for uncertain facts is not memory. It is a write-once, read-many error log with a conversational interface.
If consumer ChatGPT cannot manage memory cleanly with billions in funding and years of research, what chance does your production agent stack have? The answer is not flattering, and pretending otherwise is how you ship a liability.
Why Every Framework Gets It Wrong
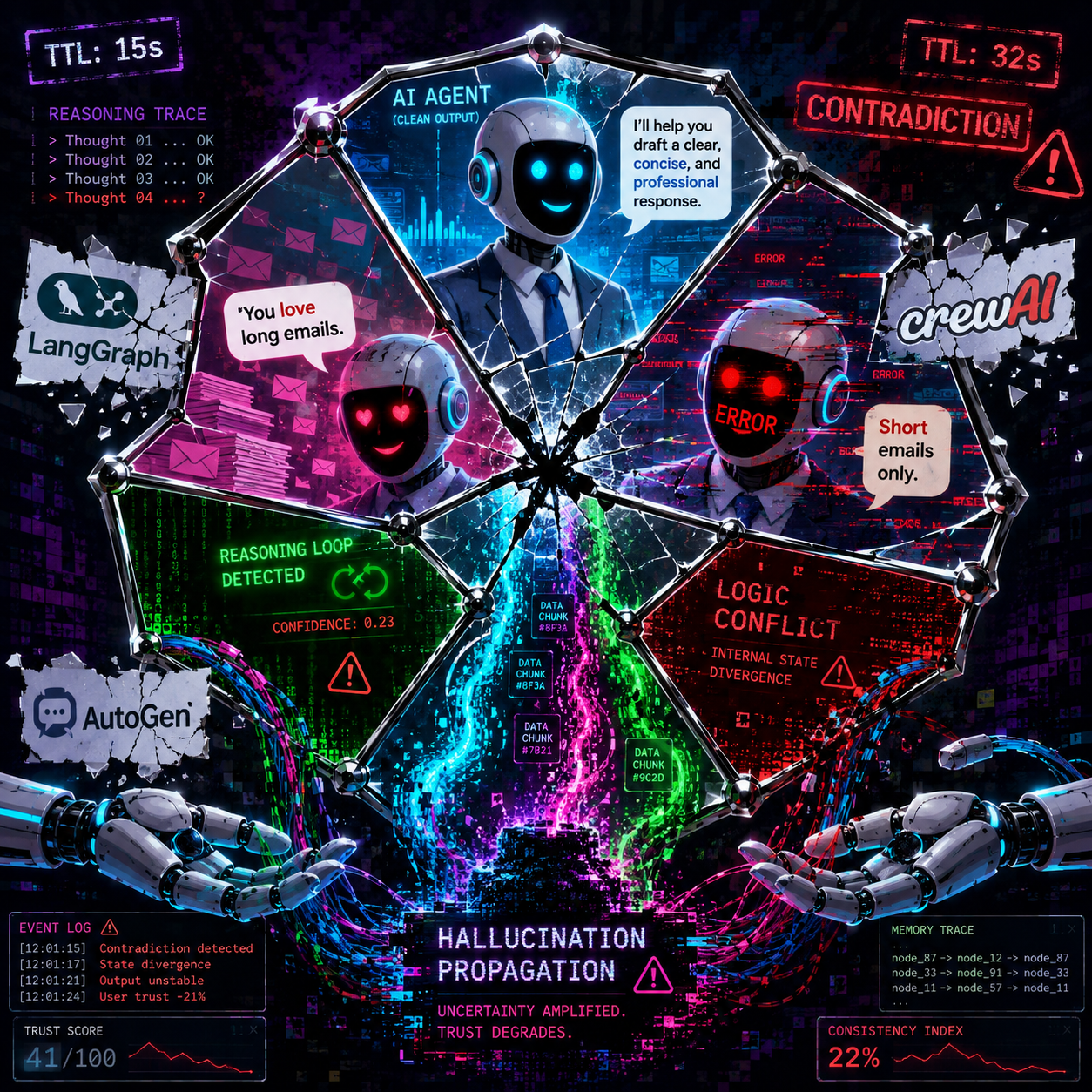
Look at how the major agent frameworks handle persistent state. None of them get it right, because none of them treat memory as a distributed systems problem.
LangGraph uses graph-based state persistence with checkpointing. The state of each node in the graph is saved, so you can resume workflows. But there is no native staleness detection. A fact written to a checkpoint three weeks ago is treated with the same confidence as a fact from yesterday. No TTL. No versioning. No mechanism to flag that a stored belief may have expired while the workflow was paused. In distributed systems terms, LangGraph gives you durability without eventual consistency guarantees.
CrewAI enables agent-to-agent memory sharing. Multiple agents can read and write to a shared memory layer, which sounds like progress until you realize there is no conflict resolution. Two agents can hold contradictory beliefs about the same entity, and CrewAI has no reconciliation protocol. In a real distributed system, this is called a split brain, and engineers spend careers preventing it. In CrewAI, it is called a feature.
AutoGen uses group chat history as its memory mechanism. Every message in a multi-agent conversation becomes part of the persistent context. The problem is that group chats amplify hallucination. One agent says something incorrect, another agent picks it up and repeats it, and soon the false claim has multiple attestations in the history. AutoGen has no mechanism to distinguish primary sources from echoed error. The result is hallucination amplification masquerading as collaborative reasoning.
The Distributed General-Purpose Agent Networks paper by Shengli Zhang and colleagues, also published on arXiv on June 15, 2026, takes this problem seriously. The authors propose a layered architecture for open peer-to-peer agent networks where heterogeneous agents discover one another, establish trust, negotiate cooperation rules, and execute tasks across boundaries. They identify three core mechanism problems that every multi-agent memory system must solve: semantic announcement propagation for collaborator discovery, verifiable identity and multi-topic reputation for cooperation governance, and semantic-gradient mechanism design for open task execution.
The paper's prototype results for reputation systems under cross-topic disguise-collusion attacks are sobering. Even with formal governance mechanisms, agents can manipulate shared memory by coordinating false signals across topics. This introduces an entirely new class of consistency failures that single-agent memory does not face. When memory is distributed, the attack surface is not just the data. It is the consensus protocol itself.
Meanwhile, the Beyond Parallel Sampling paper by Sidhaarth Murali and colleagues, another June 15 arXiv submission, shows how agents explore search spaces inefficiently when memory anchors them to bad initializations. The authors found that standard parallel sampling yields diminishing returns because query redundancy at the first turn causes threads to retrieve overlapping evidence. Subsequent reasoning is conditioned on this shared, potentially flawed retrieval. They propose DivInit, a training-free intervention that diversifies query initialization, and show gains of five to seven points on multi-hop QA at matched compute.
The takeaway: memory does not just store errors. It anchors agents to them. Once a bad initialization is remembered, it biases every future exploration of the same search space. This is state drift, and it is endemic to every agent framework that uses persistent context without diversity enforcement.
Structural Uncertainty and the Illusion of Reasoning
There is a deeper problem, and it comes from the models themselves.
The paper "Quantifying Consistency in LLM Logical Reasoning via Structural Uncertainty," by Baishali Chaudhury and colleagues and accepted as best paper at the ICLR 2026 Workshop on Logical Reasoning of Large Language Models, demonstrates that LLMs can arrive at correct answers through reasoning paths that are unstable, contradictory, or difficult to rank consistently. The authors propose structural uncertainty as a new metric, derived from the stability of self-preference rankings over sampled reasoning solutions. They generate multiple candidate solutions, ask the model to judge pairwise preferences among its own outputs, and decompose the signal into two entropy-based components: across-trial ranking instability and within-trial candidate ambiguity.
Across five LLMs and eight benchmarks, the structural signals provide information complementary to answer dispersion. On logical and mathematical reasoning tasks, combining structural uncertainty with output dispersion improves identification of unreliable instances. On factual retrieval, the structural signal collapses toward uniformity, diagnosing a boundary where reasoning-level consistency evaluation stops being informative.
Now apply this to agent memory. An agent that remembers its own reasoning, not just its conclusions, compounds structural uncertainty across sessions. It recalls not just that the answer was 42, but the unstable path it took to get there. In the next session, that recalled path becomes the anchor for new reasoning. The instability of the original reasoning infects every downstream conclusion that builds on it.
The result is an agent that sounds confident but is internally inconsistent. The memory layer makes the inconsistency harder to detect because it is buried in historical context rather than visible in a single prompt. You cannot spot-check a memory. You can only spot-check a response, and by the time the response is wrong, the corrupted reasoning has already been reinforced. This is the illusion of reasoning: a system that produces coherent outputs from incoherent foundations, and uses memory to hide the incoherence across time.
What Production Memory Should Actually Look Like
So what would a production-grade agent memory system look like? Not like any of the frameworks shipping today.
First, TTL-based fact expiration. Every memory gets a shelf life. Facts about volatile domains expire faster than facts about stable ones. A user's job title changes more often than their name. A product's price changes more often than its category. Without expiration, every memory system becomes a landfill of stale data, and agents eventually drown in it.
Second, contradiction detection layers. When a new fact conflicts with an old one, the system must flag it, not silently overwrite or append. Versioning is not enough. The system needs to surface conflicts to the agent's reasoning layer so it can weigh evidence, not just store multiple truths and hope the prompt sorts it out.
Third, hallucination quarantine. Isolated memory segments that cannot propagate until verified. If an agent generates a claim without retrievable evidence, that claim goes into quarantine. It can be referenced in future reasoning, but it cannot be treated as established fact until corroborated. This is the memory equivalent of a staging environment, and every production system should have one.
Fourth, reasoning provenance. Store why a fact was believed, not just the fact. If an agent concluded that a user prefers Slack over email because of three past interactions, store the interactions, not just the preference. When new evidence arrives, the provenance lets the agent re-evaluate the conclusion rather than treating the preference as immutable.
Fifth, multi-agent consensus protocols. Distributed memory requires voting, not broadcasting. When multiple agents share a memory layer, writes should require consensus. Reads should acknowledge quorum status. Conflict resolution should be explicit, not delegated to whichever agent wrote last. In distributed systems, this is basics. In agent frameworks, it is science fiction.
None of the major frameworks implement all five today. LangGraph has checkpointing without expiration. CrewAI has sharing without consensus. AutoGen has persistence without quarantine. The structural uncertainty paper tells us that even if they did, the underlying models might still poison the well with unstable reasoning.
The hard truth is that persistent memory is not a database problem. It is a distributed systems consistency problem disguised as a UX feature. Everyone is shipping it because users want agents that remember them. But remembering without consistency, expiration, or contradiction detection is not memory. It is compounding error.
The agent memory layer is where the hype crashes into computer science. The labs building the next generation of agents need to stop treating memory like a key-value store and start treating it like a consensus protocol. Until then, your agent's memory is a liability wearing a feature flag.
Get More Articles Like This
Getting your AI agent setup right is just the start. I'm documenting every mistake, fix, and lesson learned as I build PhantomByte.
Subscribe to receive updates when we publish new content. No spam, just real lessons from the trenches.
Build Real AI Infrastructure
PhantomByte teaches you to build real AI infrastructure yourself: local AI stacks, autonomous agents, multi-agent orchestration, web scraping, and custom tools. Step-by-step PDF tutorials you download, follow, and deploy. No subscriptions. No fluff. Just skills that ship.