
Every tutorial shows you the same twenty lines. A while(true) loop. Call the model. Parse the output. Invoke a tool. Repeat. It looks elegant on a slide. It collapses the moment it hits production.
A leaked analysis of Claude Code's actual agent loop, query.ts, reveals a single while(true) spanning over 1,400 lines of TypeScript. It is not a loop in any tutorial sense. It is an async generator yielding typed events (StreamEvent, RequestStartEvent, ToolUseSummaryMessage) directly to the terminal via Ink, which is React for terminals, with zero buffering between the API call and what the user sees. The model is not the hard part. The loop is.
The naive tutorial loop breaks immediately under nine conditions that have nothing to do with task completion: network timeouts, context window exhaustion, hanging bash scripts, governance hooks, laptop sleep, session loss, user interruption, API stream corruption, and edge deployment constraints. This piece walks through each one, quantifies the cost of ignoring them, and argues that the agent loop, not the model, is where the real engineering value lives.
The thesis is simple. The agent loop is not the smart part. The intelligence is entirely in the model. The loop's job is to keep things correct when production introduces conditions the model cannot handle.
The Production Agent Gap: Quick Reference
Context Compaction
Tutorial Approach: Truncate oldest messages
Production Fix: Sliding-window priority scoring and serialization
Timeout Handling
Tutorial Approach: Await tool indefinitely
Production Fix: Per-tool budgets and hang detection
Governance Hooks
Tutorial Approach: Execute immediately
Production Fix: Pre-action gates and cryptographic logging
Session Health
Tutorial Approach: Assume constant connection
Production Fix: Heartbeat pings and state serialization
User Interruption
Tutorial Approach: Ignore until turn completes
Production Fix: Interruptible state machines and rollback queues
API Resilience
Tutorial Approach: Assume perfect response
Production Fix: Stream buffering and chunk validation
Sleep Recovery
Tutorial Approach: Process dies
Production Fix: Persistent snapshots and daemonized resumes
Handoff State
Tutorial Approach: Start from scratch
Production Fix: Structured intent and state serialization
Edge Deployment
Tutorial Approach: Assume infinite cloud compute
Production Fix: Modular decomposition and structured retrieval
The Production Gap Breakdown
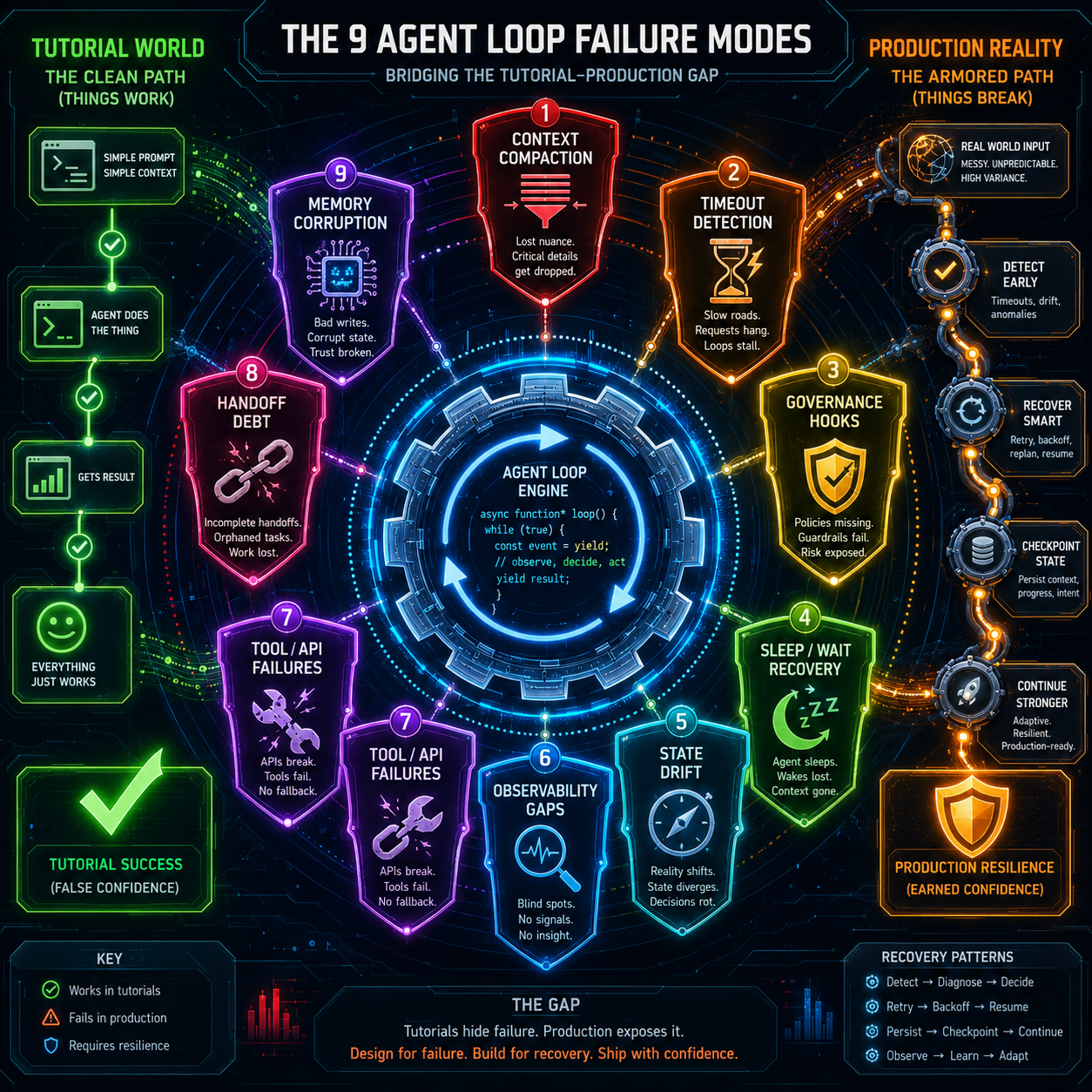
Failure Mode 1: Context Window Compaction
Long-running agents hit token limits mid-task. The naive response is truncation: cut the oldest messages and keep going. Truncation destroys task state. If the oldest message was the task definition, the agent forgets what it was doing. If it was a tool result, the agent loses the ground truth it needs to make the next decision.
The production fix is compaction, not truncation. Compaction means sliding-window analysis that scores each message by structural load-bearing capacity. Is this message a task constraint? A tool result that subsequent reasoning depends on? A governance approval that changed the agent's authority scope? Priority scoring decides which history to retain, and checkpoint serialization preserves the agent's state at deterministic boundaries so recovery does not require replaying the entire conversation.
Claude Code's query.ts implements this as an event-driven compaction pipeline inside the loop itself. The model never sees a context window error. The loop handles it before the model knows it happened. That is the difference between a tutorial and production: the tutorial assumes the model is always given a clean slate. Production assumes the slate is dirty and the agent must keep working anyway.
Failure Mode 2: Tool Execution Timeouts and Hang Detection
Bash scripts hang. API calls stall. File reads block indefinitely. The tutorial loop calls a tool, awaits the result, and moves on. In production, awaiting forever is not an option.
The production fix is per-tool timeout budgets, hang detection heuristics, partial-result capture, and graceful degradation to alternative tools. If npm install does not return in sixty seconds, the loop does not crash. It captures whatever partial output exists, marks the tool as stalled, and either retries with a different package source or escalates to the user with a structured failure report.
This is not hypothetical. A coding agent that runs npm install on a poisoned package, as noted in PhantomByte's May 20 piece on the Mini Shai-Hulud attack, will hang indefinitely without timeout enforcement. The user sees no error. The agent appears to be working. In reality, it is dead. Without a loop that enforces time budgets and detects hangs, the user never knows the difference between slow progress and a frozen process.
Failure Mode 3: Governance Hook Injection
Enterprises need audit trails. They need policy enforcement before destructive actions. They need human-in-the-loop gates before code is committed, data is deleted, or infrastructure is modified. The tutorial loop has no concept of governance. It executes whatever the model outputs.
The production fix is pre-action governance hooks, cryptographic action logging, and scoping boundaries. Before any tool execution, the loop checks whether the requested action falls within the agent's current authority envelope. If it does not, the loop pauses, logs the request, and routes it to a human approver. After execution, the loop logs the outcome with a cryptographic hash that binds the action to the specific model state that authorized it.
To solve this at an enterprise scale, researchers are developing frameworks to enforce policies without modifying the core model. For instance, the Overlaying Governance paper (arXiv 2606.03518 by Amjad Ibrahim and Yong Li) proposes a compositional authorization framework that layers governance without changing the underlying system. The framework treats delegation as a contractual term rather than a static token-based consent credential, and it introduces resource scope attenuation to bound agentic access envelopes. The paper's formal proofs show that this approach overlays new agentic semantics onto existing relational policies without rewriting them.
This matters because regulation is no longer theoretical. President Trump's executive order, signed in early June 2026, establishes a voluntary framework requiring frontier AI companies to give the federal government access to models thirty days before public release. The EU AI Act's high-risk deadline hit on May 29, 2026, and is already being enforced. Both frameworks assume auditable agent actions. The loop is where that auditability lives. The model does not know it is being audited. The loop does.
Failure Mode 4: Session and Terminal Health Monitoring
Laptops sleep. SSH connections drop. Terminal emulators crash. VPNs reconnect and change IP addresses. The tutorial loop runs on a single machine in a single terminal session and assumes both will stay alive. Production assumes neither will.
The production fix is heartbeat pings, session fingerprinting, terminal capability re-negotiation, and state serialization to durable storage. The loop sends a lightweight ping every few seconds. If the terminal does not respond, the loop checkpoints its current state to disk and enters a reconnection protocol. When the terminal comes back (whether the same session or a new one), the loop re-negotiates capabilities, restores state, and resumes without requiring the user to re-explain the task.
The financial impact of losing this session continuity is staggering. The Handoff Debt paper (arXiv 2606.02875 by Dipesh KC and Anjila Budathoki) quantified this in a way that should terrify anyone running agents without state transfer. The researchers found that repository-only handoffs (where there is no state transfer, just a fresh agent looking at the same code) cost 42 to 63 percent more prompt tokens than context-bearing handoffs. Across 75 source tasks generating 181 handoff-point tasks and 724 takeover runs per successor model, the median rediscovery cost was 20 to 59 percent additional agent events. Every time you lose a session and start over, you are paying that tax.
Failure Mode 5: User Interruption Detection
Humans step in mid-task. They issue a new command. They cancel the current operation. The tutorial loop has no mechanism for this. It is a single-threaded sequence: model, tool, model, tool. A user interrupt is an unhandled exception.
The production fix is interruptible state machines, task queuing, and rollback boundaries. The loop listens for interrupt signals continuously, not just between turns. When an interrupt arrives, the loop stops the current tool execution, marks the task as interrupted, and serializes the partial state. It then queues the new user command and evaluates whether the previous task needs rollback: did it already modify files? Did it already commit partial changes to a database? If so, the loop triggers a rollback protocol before starting the new task.
Every interruption creates a handoff point, and handoff points are expensive. The Handoff Debt paper measured this across 75 source tasks and found that structured handoff notes reduced median events by up to 59 percent compared to repository-only takeover. In other words, if your loop does not serialize intent when the user interrupts, the next agent, or the same agent resuming later, will waste more than half its effort rediscovering what it already knew.
Failure Mode 6: API Streaming Resilience
Streaming model outputs fragment. Network jitter corrupts SSE chunks. The API rate-limits mid-stream. The tutorial loop receives a complete response and parses it. Production receives chunks, and some of them are garbage.
The production fix is stream buffering, chunk validation, exponential backoff with jitter, and partial-response reconstruction. The loop maintains a buffer of received chunks, validates each one against the expected schema before appending it, and if a chunk is corrupted or the stream drops, it reconstructs what it can and requests a resumption from the last valid point. Exponential backoff with jitter prevents the loop from hammering a rate-limited API into a hard ban.
The cost of ignoring this is steep. A corrupted tool-call JSON halfway through a 4,000-token response wastes the entire generation. The model output is unusable. The tool call is unparseable. The agent must either request a regeneration (burning tokens and time) or fail the task. Stream resilience is not an optimization. It is a requirement for any agent that runs longer than a few minutes.
Failure Mode 7: Sleep and Wake Recovery
A developer closes their laptop at 11 PM and reopens it at 8 AM. They expect the agent to resume. The tutorial loop dies when the machine sleeps. Production does not get that luxury.
The production fix is persistent state snapshots, daemonized agent processes, and resumption protocols. The loop periodically serializes its full state, including conversation history, pending tool calls, checkpointed tool results, and governance approvals, to a durable store. When the machine wakes, a daemon process detects the resumption event, reloads the snapshot, and re-enters the loop at the exact point it left off. The user does not need to re-explain the task. The model does not need to re-reason from scratch.
Academic research is actively solving this persistence problem. This connects directly to DELTAMEM (arXiv 2606.03083 by Haoran Tan et al.), which proposes incremental experience memory for LLM agents via residual trees. The framework organizes experience memory into two independent residual trees: one for goal-conditioned task experience stored as reusable skills, and another for scene-level environment knowledge. Each tree uses a root node for generalized base experiences and incremental delta nodes for subsequent variations, allowing related experiences to share a common foundation without duplication. For long-running agents that sleep and wake repeatedly, this prevents context-window collapse by compressing redundant history into reusable structures rather than replaying flat logs.
Failure Mode 8: Task Handoff State Serialization
One agent starts a refactor. It gets interrupted. A fresh agent instance takes over. The tutorial assumes the same agent instance runs from start to finish. Production assumes the opposite.
The production fix is structured handoff notes, repository-state hashing, and intent serialization. When an agent stops, it does not just save the repository state. It saves what it was trying to do, why it chose that approach, what partial results it had, and what obstacles it encountered. The next agent reads this as a briefing, not a cold start.
The Handoff Debt paper tested four handoff views: repository-only, raw trace, summary notes, and structured notes. Repository-only was the baseline and the worst. Raw trace was better but noisy. Summary notes helped. Structured notes reduced median events by up to 59 percent and cumulative prompt tokens by 42 to 63 percent. The implication is brutal: context windows have lulled us into thinking state transfer is solved. It is not. Every agent framework that assumes clean handoffs is lying to itself.
The loop is where this serialization happens. The model does not know it is being replaced. The loop must capture enough context that a successor model, potentially a different model with different training, can resume without rediscovery waste.
Failure Mode 9: Resource-Constrained Deployment
Agents need to run on edge devices, embedded hardware, or laptops without cloud connectivity. The tutorial loop assumes infinite cloud compute. Production often has 4GB of RAM and no network.
To handle these rigid constraints, architecture must shift from monolithic models to distributed systems. The Modular Architecture for Embedded AI Agents paper (arXiv 2606.02862 by Marcus Rub and Michael Gerhards) proposes a tiered design that decouples On-Device Agents, executing highly compressed neural networks and rule-based logic for low-latency, privacy-critical tasks, from Cloud-Augmented Agents that leverage Small Language Models for higher-level reasoning. A cross-cutting Governance Layer ensures observability and policy enforcement across distributed fleets.
This is becoming commercially relevant. AMD's Ryzen AI Max Pro, announced at Computex 2026, is designed for local inference at scale. NVIDIA's RTX Spark, announced at Microsoft Build 2026 and integrated into the Surface RTX Spark Dev Box, brings Arm-based AI inference to portable hardware. NVIDIA and Microsoft also announced a unified agentic AI deployment stack that spans Windows devices, cloud, and local infrastructure. The hardware for local agent deployment is crossing from experimental to viable, but the software architecture (the modular loop) must be ready for it.
As these modular agents acquire more capabilities, organizing their tools becomes critical. SkillDAG (arXiv 2606.03056 by Tong Bai et al.) adds another layer. As agents adopt large skill libraries, selecting the right subset becomes a structural problem. SkillDAG models inter-skill relationships as a typed directed graph and exposes it to the agent as an inference-time structural retrieval interface. On ALFWorld and SkillsBench with MiniMax-M2.7, it reached 67.1 percent success, exceeding the strongest Graph-of-Skills baseline by 12.8 points. For resource-constrained agents that cannot afford to load every skill into context, this kind of structured retrieval is the difference between functional and unusable.
The Synthesis: Why This Matters Now
Three independent sources published on the same day about production agent architecture. The Claude Code deep-dive exposed the 1,400-line reality. The Handoff Debt paper measured the cost of getting handoffs wrong. The Modular Embedded Agents paper proposed how to run agents where cloud connectivity is a fantasy. This is not coincidence. The industry is exiting the demo phase and entering the production phase.
The gap between tutorial loops and production loops is where the next twelve months of agent engineering will be spent. For builders, the lesson is direct: before you add another tool to your agent, ask whether your loop can handle the nine failure modes above. If not, the tool is useless. A model that can write code is worthless if the loop cannot detect a hanging npm install. A model that can summarize documents is worthless if the loop loses all state when the laptop sleeps.
Ultimately, these production loops serve a fundamental business purpose: controlling costs. ToolGate (arXiv 2606.03054 by Anjie Liu et al.) makes the economic case explicit. The paper introduces a lightweight external controller that predicts execute-or-skip decisions for perceptual tool calls in vision-language agents. Across two Qwen3-VL backbones, ToolGate reduces token cost to 64 to 69 percent of the unrestricted baseline while preserving accuracy. The lesson is not just about vision-language agents. It is about the loop making smarter decisions than the model about what is worth doing. Sometimes the right move is not to call the tool at all. The loop decides. The model proposes.
The Close: The Loop Is the Product
The model gets the headlines. The loop gets the uptime.
Every major platform is racing to build the most resilient agent runtime, not the best model. OpenAI Codex is a model wrapped in a runtime. Claude Code is a runtime that happens to use a model. GitHub Copilot is migrating from autocomplete to agentic execution, which means its loop is becoming the product. Gemini Spark is Google's bet that the agent runtime matters more than the model architecture. The organizations that treat the agent loop as first-class engineering will have agents that survive production. Everyone else will have expensive demos that break on the first sleep-wake cycle.
Your next hire should not be a prompt engineer. It should be a loop engineer.
Get More Articles Like This
Getting your AI agent setup right is just the start. I'm documenting every mistake, fix, and lesson learned as I build PhantomByte.
Subscribe to receive updates when we publish new content. No spam, just real lessons from the trenches.