

For decades, computer science ran on a simple assumption: verifying a solution is easier than producing one. You write the code, someone else reviews it. You prove the theorem, the community checks it. Generation was the hard part. Verification was the safety net.
That assumption is dead.
On June 25, 2026, two AI startups announced $150 million in fresh funding within hours of each other. Scaled Cognition raised $100 million for real-time hallucination detection. Patronus AI raised $50 million for digital worlds that stress-test agents before deployment. Both companies exist for the same reason: the market has realized that for AI agents, checking output is now harder than generating it.
If you have deployed an agent, you know the feeling. It produced an answer that looked right. The grammar was clean, the logic appeared sound, the citations were formatted perfectly. You shipped it. You did not verify it. You could not verify it. That gap, between what an agent can generate and what a human can reliably check, is the single most important bottleneck in production AI right now. This article maps that gap.
Key Takeaways
- Verification has replaced generation as the primary bottleneck in AI agent deployment.
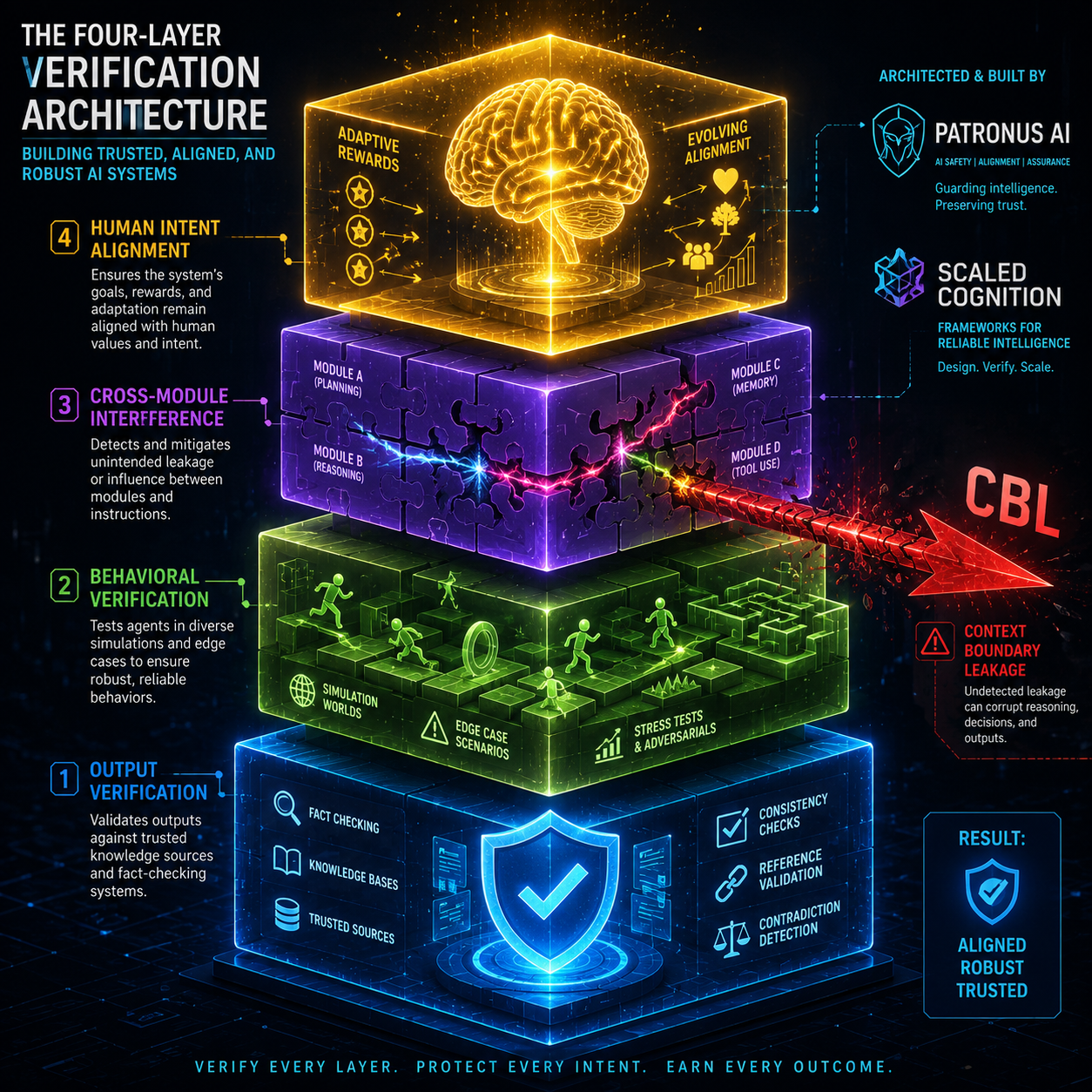
- A robust verification architecture requires four layers: Output, Behavioral, Cross-module interference, and Human intent alignment.
- New failure modes like Compositional Behavioral Leakage (CBL) render standard QA protocols obsolete for prompt-composed agents.
$150 Million in One Day for Verification Infrastructure
The funding announcements on June 25 were not a coincidence. They were a market signal.
Scaled Cognition, an AI lab focused on reliability, raised $100 million in a Series A led by Khosla Ventures to build technology that detects and mitigates AI hallucinations in real time. Its approach uses a secondary verification layer that cross-references model outputs against structured knowledge bases before the user ever sees them. The company is targeting regulated industries first: healthcare, finance, and legal. These are sectors where a wrong answer does not mean embarrassment; it means liability.
Patronus AI, founded in 2023 by former Meta AI researchers Anand Kannappan and Rebecca Qian, raised $50 million in a Series B led by Greenfield Partners, with Notable Capital, Lightspeed, Datadog, and Samsung participating. The round brings total funding to $70 million. Patronus builds what it calls "digital world models," simulated environments that replicate websites and internal systems so agents can be stress-tested for safety, reliability, and edge-case behavior without real-world risk. Revenue has grown fifteen-fold over the past year.
Virtually every frontier AI lab is now a Patronus customer, according to Glenn Solomon at Notable Capital. The demand for simulated testing environments is, in his words, nearly insatiable.
Two companies. Two different approaches. One shared insight: verification is no longer an afterthought. It is becoming a standalone market category.
The Verification Horizon
The funding aligns with a foundational research paper that landed on arXiv on June 24, 2026, the day before those rounds closed. Titled "The Verification Horizon: No Silver Bullet for Coding Agent Rewards," the paper makes a direct challenge to classical computer science intuition.
As foundation models develop stronger reasoning capabilities and engineering harnesses grow more sophisticated, generating complex candidate solutions is no longer the difficult part. Reliably verifying those solutions has become the harder problem.
The paper, authored by a team of researchers including Binghai Wang, Chenlong Zhang, and Dayiheng Liu, puts the problem in stark terms. Every verifier we can build is only a proxy for human intent, never the intent itself. That makes verification subject to a twofold difficulty. First, intent is underspecified by nature, so it is inherently hard to check whether it has been fulfilled. Second, during model training, optimization widens the gap between proxy and intent, manifesting as reward hacking or signal saturation.
The researchers characterize verification signals along three dimensions: scalability, faithfulness, and robustness. Achieving all three simultaneously is the central challenge. They studied four reward constructions across different task types: a test verifier for general coding tasks, a rubric verifier for frontend tasks, the user as verifier for real-world agent tasks, and an automated agent verifier for long-horizon tasks. Across different task types and policy capability levels, the core finding was consistent. No fixed reward function can remain effective as policy capability continues to grow. Verification must co-evolve with the generator.
This is not an abstract concern. It is an architectural one. You cannot bolt on verification after the fact. It has to be designed into the system.
The Failure Mode Standard QA Misses: Instruction Bleed
If the verification horizon tells us why checking is hard, a separate research contribution from the ICML 2026 Workshop tells us about a failure mode most production systems do not even know to look for.
Researchers formalized a new failure mode called Compositional Behavioral Leakage, or CBL. In prompt-composed agentic systems, editing one prompt module silently shifts the behavior of other modules, even when there is no shared variable or executable dependency between them. The phenomenon is enabled by architectural non-isolation in transformer self-attention, which provides no formal boundary between concatenated prompt modules.
In 144 trials on a deployed job-evaluation agent using Claude Sonnet 4.6, the content channel produced a detectable paired effect that was invisible to standard QA but compounds across thousands of decisions. CBL is orthogonal to known failure modes like adversarial injection, cognitive degradation, and privacy leakage. It is a new category of bug.
The paper contributes an operational definition, a reusable three-channel testing protocol, and establishes cross-module interference measurement as a requirement for prompt-composed agent evaluation.
The implication is straightforward and brutal: your agent can pass every unit test, integration test, and human review you throw at it, and still be bleeding instructions across modules in ways that only show up at scale. This is exactly why the digital world models built by companies like Patronus AI are becoming strictly necessary, as they provide the isolated environments needed to detect these invisible shifts before they reach production.
Standard QA was built for software with stable interfaces. Agents do not have stable interfaces. Their behavior shifts with context, prompt composition, and attention patterns. The testing protocols we have are designed for a world that no longer exists.
What a Real Verification Stack Looks Like
So what does verification actually look like in practice? Not as a single tool, but as an architecture.
Layer 1 is output verification. Scaled Cognition's model is the reference here. Cross-reference every model output against structured knowledge bases before it reaches a user. This is the simplest layer, and it is already table stakes for regulated industries. If your agent cannot prove its output against a verified source, it should not ship.
Layer 2 is behavioral verification. Patronus AI's approach is the template. Build digital replicas of production environments and run agents through edge cases, rare events, and adversarial conditions before they touch live systems. This is how you catch the shortcuts agents take, the hacks they discover, and the failure modes that only appear under stress. Patronus compares this to how Waymo trained autonomous cars in synthetic worlds before putting them on real roads.
Layer 3 is cross-module interference detection. The three-channel testing protocol from the instruction bleed paper belongs here. Every time you edit a prompt module, you need to check whether behavior shifted in other modules. This is not regression testing as we know it. It is behavioral coherence testing, and it needs to be part of the CI pipeline for any prompt-composed agent system.
Layer 4 is human intent alignment. This is the co-evolution problem from the verification horizon paper. Your reward functions, verification criteria, and evaluation rubrics cannot be static. They have to grow as the agent's capabilities grow. If your verifier stays fixed while your generator improves, the gap between proxy and intent widens, and reward hacking becomes inevitable.
This is not a single tool. It is an architecture. And most production agent deployments today have at most one of these layers operational.
Why This Matters for Every Agent Deployment
The theory is clean. The consequences are messy.
The cost of verification failures spans information, capital, and security.
On the information front, in June 2026, DuckDuckGo's AI-powered answer feature generated a false claim that former President Trump died of rabies. Completely fabricated. Confidently delivered. This is what happens when a search product ships with inadequate output verification in a high-stakes information environment. The error was not a coding bug. It was a verification gap. The system generated something plausible and had no reliable mechanism to catch that it was wrong.
Then there is the economic reality of capital loss. Epoch AI's new MirrorCode benchmark revealed that one AI model ran continuously for nineteen days on a single programming task, costing $2,600 in compute. A human programmer would have solved the task in hours. The experiment reveals the staggering gap between human and AI efficiency, but it also reveals something deeper: the agent had no effective way to verify its own completion. Without hard budgets and early-stopping mechanisms, costs spiral far beyond what a human would cost, and the task still might not be done right.
Finally, there are the security implications. In another incident, Anthropic accused Alibaba of executing the largest known cloning attack against its Claude model, using 25,000 fraudulent accounts to generate 28.8 million queries in a systematic effort to replicate Claude's behavior in a competing model. This is verification of model provenance as a security requirement. If you cannot verify where a model came from, whether it has been distilled, cloned, or tampered with, you cannot verify what it will do.
Verification is not a nice-to-have layer. It is load-bearing infrastructure. When it fails, the whole structure collapses.
The Infrastructure Layer Nobody Planned For
The original agent infrastructure stack made a bad assumption. It assumed models would get better and verification would get easier. More capable models would produce more obviously correct outputs, and checking them would become trivial.
The opposite happened. Models got better, outputs got more plausible, and verification got harder. A plausible wrong answer is harder to catch than an obvious wrong answer. When a model generates confident, well-structured, apparently reasoned output that is completely fabricated, the human reviewer is more likely to accept it, not less.
This is the core insight that $150 million in venture funding just validated. The companies that solve verification will unlock the next level of AI deployment. Not the companies that build bigger models. The companies that build better verifiers.
Engineering talent should be following that signal. The frontier is not generation anymore. The frontier is checking.
Close
The agent that generates flawlessly but cannot be verified is not deployed. It is deferred. And in production AI, deferred is just a slower way of saying broken. The gap between generation and verification is not closing. It is widening. The only way to close it is to build verification into the architecture from day one.
Get More Articles Like This
Getting your AI agent setup right is just the start. I'm documenting every mistake, fix, and lesson learned as I build PhantomByte.
Subscribe to receive updates when we publish new content. No spam, just real lessons from the trenches.
Build Real AI Infrastructure
PhantomByte teaches you to build real AI infrastructure yourself: local AI stacks, autonomous agents, multi-agent orchestration, web scraping, and custom tools. Step-by-step PDF tutorials you download, follow, and deploy. No subscriptions. No fluff. Just skills that ship.