
When half a million lines of proprietary code hit the public domain overnight, the veil lifted on one of the most sophisticated AI coding agent systems ever built. The Claude Code source code leak didn't just expose implementation details; it laid bare the architectural decisions that separate enterprise-grade AI agents from experimental prototypes.
As an indie builder running local agent swarms through OpenClaw, I've spent the past weeks dissecting this codebase. What emerged is a masterclass in autonomous agent architecture, complete with guardrails that inspire both respect and frustration.
What Actually Leaked: Beyond the Headlines
The 512,000-line dump represents Claude Code's complete agentic layer. This is not the base Claude model, but the orchestration system that turns LLM outputs into executable development workflows. This is the machinery Anthropic built to handle real-world software engineering: multi-step reasoning, tool invocation, file system operations, and self-correction loops.
The leak spans three critical domains:
- KAIROS: The autonomous execution engine
- Security validators: Bash command sandboxing and validation pipelines
- Permission architecture: Enterprise access control and audit systems
For builders like us, this is better than documentation. This is production-grade source code showing exactly how Anthropic solved problems we're all wrestling with: how do you give an AI agent real power without giving it the keys to destroy everything?
KAIROS: Anthropic's Autonomous Agent Mode Explained
KAIROS isn't just a feature flag; it's a complete architectural mode that fundamentally restructures how Claude Code processes tasks. When enabled, the system shifts from reactive tool-use to proactive planning and execution.
The Architecture Under the Hood
The leaked code reveals KAIROS operates on a three-layer reasoning stack:
1. Intent Decomposition Layer
Natural language requests get broken into discrete, verifiable subtasks. It doesn't just process "build a login system," but instead handles granular steps like "validate auth module existence," "check database schema compatibility," and "generate password hash utilities." Each step becomes a node in an execution graph with explicit dependencies.
2. Execution Planning Engine
KAIROS maintains an internal world model representing file system state, tool availability, and task dependencies. This isn't reactive. It pre-computes execution paths, identifies potential conflicts, and sequences operations for minimal side effects. The leaked code shows they use a modified topological sort with backtracking for when assumptions fail.
3. Self-Correction Feedback Loops
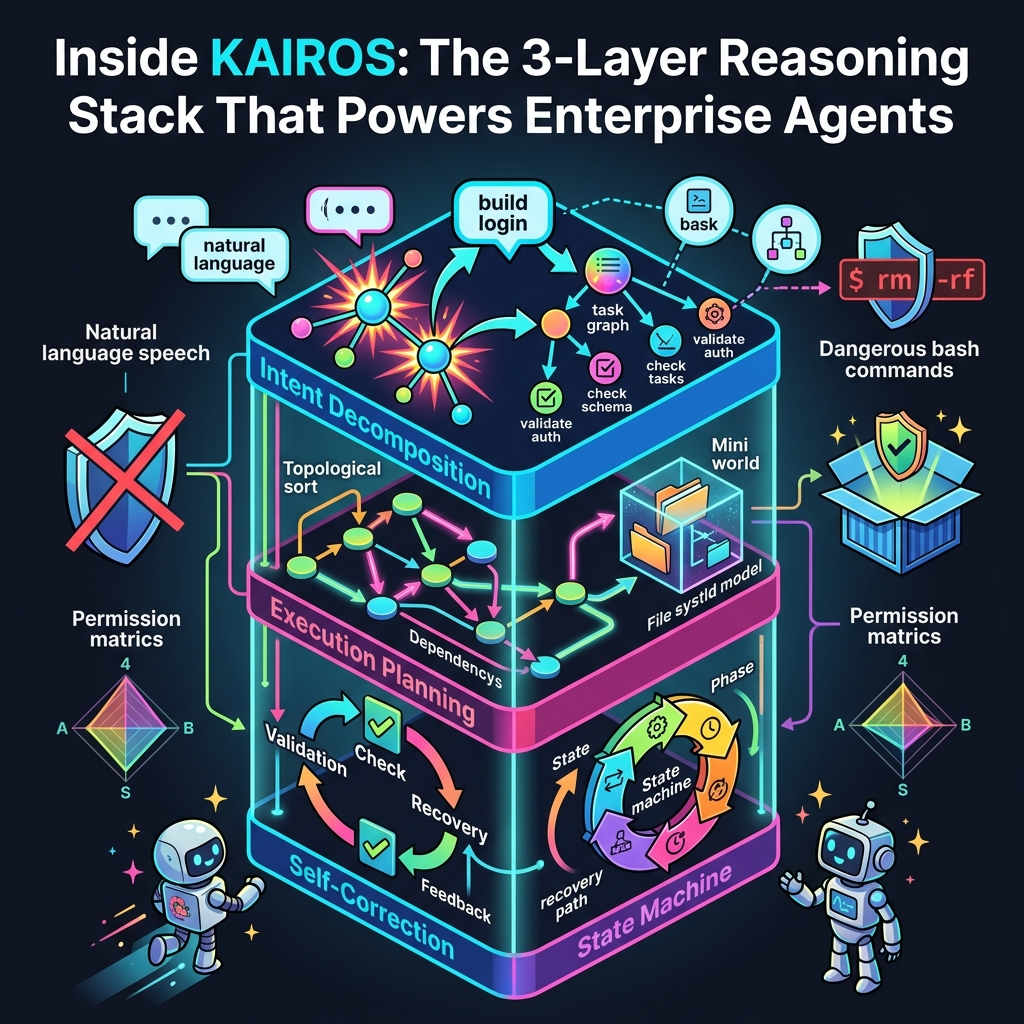
Every tool invocation returns to a validation layer that checks: Did the expected file get created? Did the command return the predicted exit code? Are there new errors in the project? Failed validations trigger replanning, not just retry logic. This is where KAIROS gets interesting. It's not just executing; it's continuously rebuilding its understanding of the current state.
The State Machine Nobody Talks About
The most revealing discovery is that KAIROS runs a formal state machine with six distinct phases: IDLE, PLANNING, EXECUTING, VALIDATING, RECOVERING, and COMPLETED. Each phase has entry guards, exit conditions, and timeout handlers.
For example, the RECOVERING phase isn't just "try again." The leaked code shows it evaluates the issue. Was this a transient failure (network timeout)? A semantic failure (wrong file modified)? Or a fundamental plan flaw (impossible dependencies)? Each failure type triggers a different recovery strategy: retry, replan, or escalate to the user.
This is enterprise-grade robustness. Compare this to simple OpenClaw tool chains where we usually handle errors with basic try-catch blocks and hope for the best.
Bash Security Validators: Lessons in Paranoia
If there's one section every indie builder should study, it's Anthropic's command validation pipeline. They've essentially built a compiler for bash that executes in three passes before any command touches the shell.
The Three-Pass Validation System
Pass One: Static Analysis
Before execution, every command string flows through a parser that identifies:
- Command type (safe read-only vs. potentially destructive)
- File path targets (absolute vs. relative, project scope vs. system-wide)
- Environment variable dependencies
- Subshell and pipeline complexity
The leaked code shows they maintain an allowlist of "safe" read commands (cat, grep, ls with specific flags) that skip heavy validation. Everything else gets flagged for deeper inspection.
Pass Two: Dynamic Sandbox Validation
Here's where it gets clever. Potentially destructive commands get executed in a disposable container first. The system captures filesystem changes, network activity, and process tree modifications. If the dry run produces unexpected side effects, execution halts.
The leaked implementation uses a lightweight container runtime (which appears to be custom, not Docker) that spins up in ~200ms. That's fast enough to not kill the user experience but thorough enough to catch "rm -rf /" before it happens.
Pass Three: User Authorization Layer
Even after passing automated validation, destructive operations require explicit user consent. But Anthropic didn't just slap on a confirmation dialog; they built contextual authorization. The system generates natural language summaries: "This will modify 3 files in src/auth/ and delete 1 file in tests/. Proceed?"
Compare this to OpenClaw's approach. We typically run commands in isolated shells with restricted permissions, but we don't have the compute budget for pre-execution dry runs in disposable sandboxes. The trade-off is clear: safety versus speed.
The Regex Patterns They Use
The leaked validators include regex patterns for detecting:
- Dangerous deletion patterns (rm.*-rf, >\s*/[^\s])
- System modification attempts (/etc/, /usr/bin/, systemctl)
- Network exfiltration (curl.*-d, wget.*-O\s*-)
- Credential exposure (hardcoded API keys, password patterns)
These aren't just defensive; they're educational. If you're building agent tooling, these patterns are battle-tested detection heuristics.
Permission Models: Enterprise Guardrails Exposed
The leaked permission architecture reveals how Anthropic balances capability with accountability. This isn't just about "can the agent delete files?"; it's about "can we trace every action back to a business objective?"
The Four-Dimensional Permission Matrix
Anthropic's system evaluates permissions across four axes:
1. Scope Dimensions
- Project-level: Can access current workspace only
- Repository-level: Can access connected git repositories
- Organization-level: Can access shared resources and secrets
- System-level: Can access OS APIs and external tools
2. Action Classes
- Read: File inspection, search, analysis
- Write: File modification, code generation
- Execute: Shell commands, build processes
- Admin: Configuration changes, tool installation
3. Risk Tiers
- Safe: Operations with no side effects
- Destructive: Operations that modify state
- Irreversible: Operations that cannot be undone
- Sensitive: Operations involving credentials/secrets
4. Authentication Context
- User-verified: Explicit approval obtained
- Session-granted: Approved for this session only
- Policy-allowed: Matches organizational policies
- Auto-approved: Whitelisted safe operations
Every tool invocation gets scored across this matrix. High-risk combinations trigger additional approvals, while safe combinations proceed automatically.
Audit Trails That Actually Matter
The leaked code includes an event logging system that captures:
- The exact LLM prompt that generated the action
- Tool parameters and execution context
- User approval timestamps and fingerprints
- Success/failure outcomes with error traces
This isn't just for debugging; it's for compliance. Enterprise customers need to prove what their AI agents did, when, and why. The system generates immutable audit logs that survive session termination.
For OpenClaw users running local swarms, we get the opposite: ephemeral execution with no audit trail unless we build it ourselves. There's a middle ground here worth considering.
Comparison: Enterprise Claude vs. OpenClaw Infrastructure
Running this analysis, I kept asking: how does this compare to my OpenClaw setup? The differences reveal trade-offs every builder needs to understand.
Reasoning Architecture
Claude Code (KAIROS):
- Centralized planning with a global world model
- Formal state machines with recovery protocols
- Pre-computed execution graphs with dependency resolution
- Heavyweight validation at every step
OpenClaw Approach:
- Distributed tool chains with minimal coordination
- Reactive execution, reacting to outputs, and planning the next step
- Lighter validation (often just shell restrictions)
- Faster iteration and less overhead (using tools like Pi with Ollama)
The verdict: KAIROS wins on robustness for complex multi-step tasks. OpenClaw wins on speed and resource efficiency. For simple workflows, the overhead isn't worth it. For critical infrastructure changes, KAIROS's paranoia pays off.
Security Posture
Claude Code:
- Three-pass command validation
- Disposable execution sandboxes
- Contextual user authorization
- Immutable audit logging
OpenClaw:
- Permission-based tool restrictions
- Isolated shell environments
- User-controlled approval flows
- Optional logging (not enforced)
The verdict: Anthropic's approach is more comprehensive but computationally expensive. OpenClaw's lean model assumes the user understands their tools, offering fewer guardrails and more direct control. Choose based on your risk tolerance and compute budget.
Scalability Patterns
Claude Code:
- Monolithic but modular architecture
- Stateful session management
- Resource-intensive validation layers
- Optimized for single-user, long-running sessions
OpenClaw:
- Distributed across multiple tools and processes
- Stateless tool executions
- Minimal overhead per operation
- Designed for multi-agent swarms
The verdict: Different optimization targets. Claude Code optimizes for reliability in complex tasks. OpenClaw optimizes for parallel execution and swarm coordination.
Indie Developer Takeaways: What to Steal, What to Skip
After weeks in this codebase, here's what I'm actually implementing in my own agent swarms, and what I'm leaving for the enterprises with bigger budgets.
Steal This: Intent Decomposition
Break down user requests into verifiable subtasks before execution. You don't need KAIROS's full state machine, but the principle of "plan first, execute second" prevents half-finished messes. I added a simple planning layer to my OpenClaw workflows that generates a task list before touching files. It is a game changer.
Steal This: Contextual Authorization
Explain what you're about to do in natural language before asking permission. "Can I run this command?" becomes "This will delete node_modules/ and reinstall dependencies (est. 2 minutes). Proceed?" It is a 10-minute implementation with a massive UX improvement.
Skip This: Disposable Sandboxing
Unless you're processing untrusted code or have enterprise liability concerns, the 200ms spin-up time per command isn't worth it for most indie workflows. Use restricted shell environments and careful regex validation instead. It is good enough for 95% of use cases at 5% of the compute cost.
Steal This: Audit Logging (Selectively)
Build event logging for high-risk operations, even if you skip the full compliance suite. When something breaks (and it will), you'll want to know exactly what the agent did. I log file modifications and command executions; I skip read operations to keep the noise down.
Skip This: Formal State Machines
Beautiful architecture, but overkill for most agent swarms. Simple try-catch with retry logic handles most failure modes. Reserve state machines for critical, multi-step workflows where partial failure is expensive.
The Honest Truth
Anthropic built Claude Code for enterprise customers who need compliance, audit trails, and liability protection. As indie builders, we can move faster with lighter guardrails, but we should understand what we're trading away.
The 512K-line leak is a gift. It shows exactly how the best-funded AI lab in the world solved autonomous agent architecture. Take the patterns that fit your scale, skip the bureaucracy that doesn't, and keep building.
Conclusion
The Claude Code source code leak is more than a security incident; it's an unsolicited architecture course from one of the most capable AI engineering teams on the planet. KAIROS reveals how to build agents that plan, recover, and validate their way through complex tasks. The security validators show the cost of comprehensive protection. The permission models demonstrate what enterprise accountability looks like.
For OpenClaw users and indie agent builders, the lesson isn't to replicate Anthropic's complexity. It's to understand the problems they're solving and choose which ones matter for your use case.
Sometimes a simple tool chain beats a state machine. Sometimes validation saves your project. Knowing the difference is what separates demos from production systems.
The leak gave us the blueprints. What we build with them is up to us.
Get More Articles Like This
Getting your AI agent setup right is just the start. I'm documenting every mistake, fix, and lesson learned as I build PhantomByte.
Subscribe to receive updates when we publish new content. No spam, just real lessons from the trenches.