
If you are new to AI agents, you will probably make the same mistake almost everyone makes at the start: you will assume the biggest model wins.
That sounds logical. Bigger model, bigger context window, more parameters, more intelligence. End of story.
Except that is not how agent systems behave in the real world.
The truth is much simpler. The best AI agent orchestration for beginners is not about choosing the most impressive model on a leaderboard. It is about choosing the model that can reliably think, call tools, delegate work, and recover when a workflow gets messy. Build the perfect system for your use case, not someone else's.
That difference matters a lot more than most people realize.
We learned that the hard way at PhantomByte. Our orchestration layer had been leaning on a giant generalist model. On paper, it looked like the obvious choice. In practice, when that layer started failing, we got a very clear reminder of something most beginners do not hear early enough: a powerful model is not the same thing as a dependable orchestrator.
That is why this comparison matters.
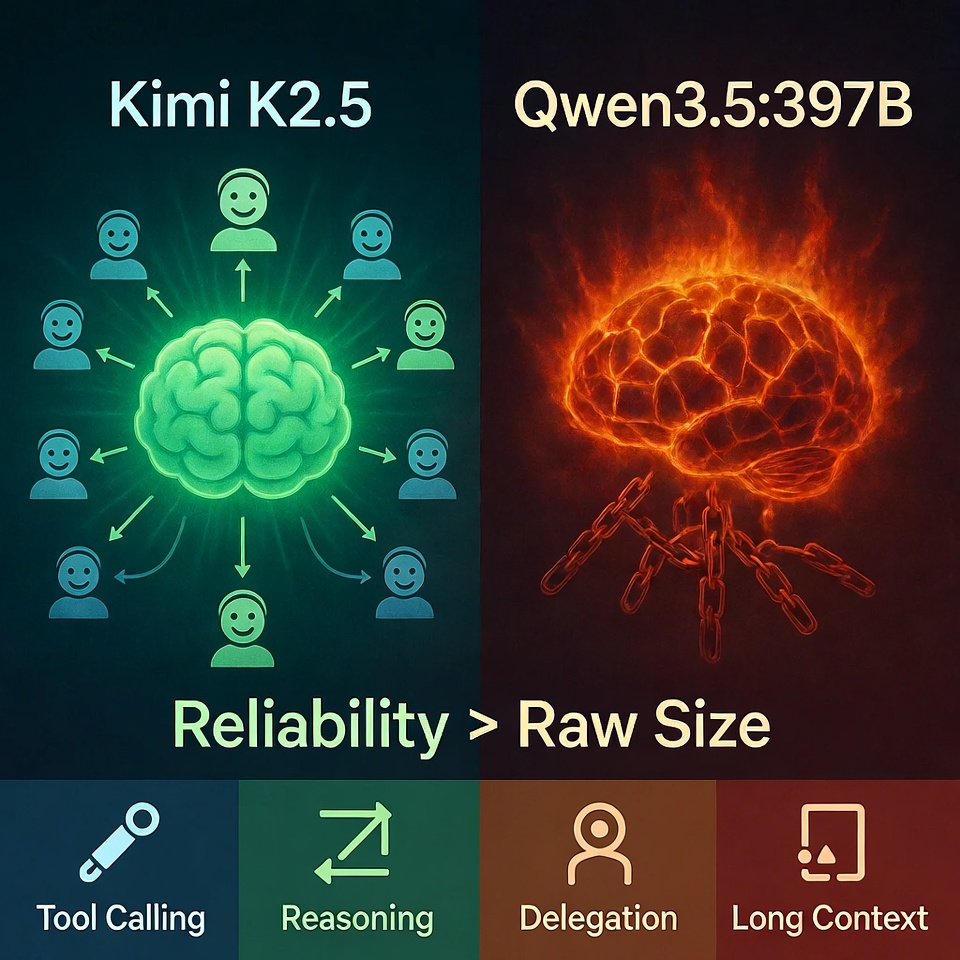
Kimi K2.5 and Qwen3.5:397B are both serious models. Both are capable. Both can look excellent in isolated demos. But once you put them inside an actual agent workflow, their personalities split fast. One tends to move through orchestration tasks with much less friction. The other can feel like it is fighting the system, the prompt, and the tool layer all at once.
For beginners, that gap is everything.
A stronger way to think about this is workflow first, model second. Recent Google Research found that multi agent systems can produce large gains on parallelizable work but can also perform much worse on sequential tasks, while McKinsey's review of more than 50 agentic AI builds emphasized workflow design, feedback loops, governance, and infrastructure over flashy agent demos. In other words, orchestration is not just about intelligence. It is about fit.
So let us get to the question behind the hype: if you are trying to build your first real agent system, which model actually gives you the better foundation?
Start with the obvious comparison
Kimi K2.5 feels like a model designed for orchestration. It has a cleaner tendency toward structured delegation, better behavior when tools are involved, and a more natural fit for workflows where one model needs to coordinate other steps. Its Agent Swarm architecture was built specifically for this, supporting up to 100 coordinated sub-agents and handling over 1,500 tool calls within a single workflow. That is not a marketing number. That is the infrastructure being designed around orchestration from the ground up.
Qwen3.5:397B feels different. It is powerful, often impressive, and clearly capable, but it can become fragile in the exact places beginners need reliability most.
That is the core mistake people make: they compare models like chatbots. Instead, they should be comparing them like operating systems for agent workflows. When you do that, the conversation changes.
The first place it changes is tool calling
For a beginner, tool calling is not some advanced feature sitting off to the side. It is the backbone of any useful agent. The moment your model needs to search, extract, route, summarize, browse, write files, or hand off work to another component, tool use stops being optional.
And this is where clean demos fall apart.
In a real workflow, reliable tool calling means the orchestrator recognizes the job, picks the correct action, formats the call properly, waits for the result, and continues the chain without losing the thread. When that loop works, the agent feels smart. When it does not, everything feels broken even if the model itself is technically strong.
That is the dealbreaker in this comparison.
Kimi K2.5 tends to handle tool workflows in a way that feels usable. It gets out of its own way. You spend less time fighting formatting issues, less time correcting broken calls, and less time wondering whether the model understood the task or just generated something tool shaped.
Qwen3.5:397B is more complicated. It can absolutely produce strong outputs. It can reason through difficult prompts. It can look excellent in standard generation tasks. But once orchestration depends on consistent tool behavior, the experience becomes far less forgiving. For an advanced builder with patience, that can be manageable. For a beginner, it becomes a tax.
And beginner tax is what kills momentum.
The same problem shows up in reasoning
A lot of people talk about reasoning as if it only matters for math or puzzle solving. In agent systems, reasoning matters because the orchestrator must decide what to do next. It needs to break a goal into smaller tasks, decide which tasks can happen in parallel, decide what needs tools, decide what needs another agent, and avoid losing the objective halfway through the chain.
That is real orchestration.
Kimi K2.5 has a more natural feel for that style of work. It behaves more like a coordinator. Qwen3.5:397B often feels like a very smart engine that still needs firmer steering. That difference may sound subtle, but beginners feel it immediately. One model helps you build. The other asks you to keep compensating for it.
Now add context length to the conversation
This is a topic that is greatly underestimated and something most people do not track as closely as they should. Big context numbers look amazing in specs. They also make for easy marketing. But beginners should care less about the headline number and more about whether the model stays coherent when the context actually gets long.
That is where a lot of people get fooled. To be perfectly honest, it is not always easy to tell until it is too late.
A large context window only matters if the model can hold the thread across long prompts, multiple tool results, previous decisions, delegated tasks, and changing objectives. In agent systems, long context is not just a giant document. It is a moving workspace.
That is why orchestration quality matters more than context bragging rights.
Kimi K2.5 has a stronger case when the job involves long chains of instructions, delegated subtasks, or extended document work. Qwen3.5:397B can still perform well, but the practical question for beginners is simple: which model loses the plot less often when the workflow gets messy?
That is the question you should optimize for.
Speed matters too, but probably not in the way most people think
A faster model is nice. Lower latency is nice. Better throughput is nice. But in orchestration, raw speed only helps if the workflow completes correctly. A fast orchestrator that breaks the chain is still slower than a steadier one that finishes the job without intervention. Multiple prompts cost money, so keep that in mind.
This is where many beginners accidentally optimize for the wrong metric.
They see lower cost or lower latency and assume that means better workflow performance. In reality, the cheapest step in any agent system is usually the one that does not need to be repeated. The most expensive workflow is the one that stalls halfway through, forces manual cleanup, or quietly produces bad handoffs.
That brings us to the bigger lesson behind this article
The real debate is not Kimi versus Qwen in isolation. It is generalist thinking versus orchestration thinking.
For years, the instinct in AI has been to chase a super brain. One massive model to handle everything: planning, reasoning, execution, delegation, memory, and tool use. It sounds elegant. It also creates a hidden single point of failure.
We saw that firsthand.
When your whole system depends on one giant layer doing everything, any instability at that layer ripples outward. The workflow does not just slow down. It becomes fragile. One issue upstream turns into broken delegation, missing tool calls, confused state, and stalled output downstream.
The deeper lesson for beginners is that agent architecture should behave more like a team than a throne. You do not need one model carrying the entire burden. You need a reliable orchestrator coordinating specialized workers that stay in their lane. For me personally, I like having an orchestrator with the ability to spawn agents natively, which is why I am using Kimi K2.5 as my orchestrator.
That architecture also fits what current research is showing. Google Research reported that agent systems can outperform a single agent on work that benefits from parallel coordination, but can degrade sharply on sequential tasks where coordination overhead gets in the way. That does not mean multi agent is always better. It means the orchestrator has to understand what kind of work it is managing.
That is exactly why beginners should care about the orchestrator model. If the coordinator is unstable, the whole stack feels unstable. If the coordinator is dependable, even smaller supporting models become much more valuable.
Most people reading comparison pieces are still thinking at the model level
They are asking which model is smarter. Which one is cheaper. Which one has the bigger number. Very few are asking the better question: which one can actually coordinate sub agents in a way that survives real workflows?
OpenClaw allows models to spawn sub agents. On paper, that means many models can participate in complex delegated systems. In practice, reliability decides everything. A model that can technically spawn sub agents but regularly fails during tool use, handoff, or multi step reasoning is not giving you orchestration. It is giving you extra failure points.
That is why Kimi looks stronger in this specific role. Its combination of reasoning, structure, and tool behavior makes sub agent delegation more realistic. Qwen3.5:397B may still have the horsepower, but horsepower alone is not enough when the workflow depends on consistent execution.
And that leads directly into the business lesson
A lot of beginners still treat agent failure as a prompt problem. They assume they just need better wording, better system instructions, or a cleverer chain. Sometimes that helps. But once you start building real workflows, many failures are architecture failures, not prompt failures.
McKinsey's synthesis of enterprise agent deployments emphasized that success depends on end to end workflows, continuous improvement, governance, and infrastructure built for scaling, not just on whether the agent looks impressive in isolation. That is the practical reality most "best model" articles ignore.
For beginners, that insight is huge. It means you should stop asking, "What is the smartest model I can afford?"
Start asking, "What is the most reliable orchestrator I can build around?" Those are not the same question.
So who should choose which model?
If you are building a real agent system, especially one that needs tools, sub agents, long context, or workflow resilience, Kimi K2.5 is the easier recommendation. It is the better starting point for orchestration heavy use. It reduces friction in the exact places beginners usually get stuck.
If your priority is cost control, experimentation, or local testing with a huge model you are willing to babysit, Qwen3.5:397B still has a place. It remains interesting. It remains powerful. It remains worth watching. Worth noting: Qwen3.5:397B uses a sparse mixture of experts architecture where only 17 billion parameters are active per token, which is why it can run at a fraction of the cost of a true 397B dense model. That makes it an excellent option for operating simple workflows that do not require spawning agents. But the honest framing is this: right now it looks more suitable for experimentation than for a beginner friendly production orchestrator.
That is not an insult. It is an operational distinction. And it is an important one. Because beginners do not need the model with the most theoretical upside. They need the model that helps them finish a working system.
That is the verdict most spec sheet comparisons miss.
The verdict
The biggest model is not automatically the best AI agent orchestration choice for beginners. In many cases, the better choice is the model that keeps the workflow alive, keeps tool calls stable, keeps delegation clean, and keeps your system from collapsing when one layer gets messy.
That is why Kimi K2.5 wins this comparison for beginners, not because Qwen3.5:397B is weak. Because orchestration rewards reliability more than raw size. And that is also why the broader PhantomByte story matters.
When our primary layer failed, the lesson was not just "have a backup." The lesson was that resilient AI systems should be built around specialization, adaptability, and clean orchestration from the start. A giant generalist can look unbeatable until the moment it becomes your bottleneck.
Once you see that, you stop chasing the super brain. You start building the swarm.
In 2026, that may be the most important mindset shift in AI architecture. Google Research has already shown that the value of agent systems depends heavily on task structure, not on a blanket assumption that more agents are always better. The winners will not be the teams with the biggest models alone. They will be the teams that know when to centralize, when to delegate, and which orchestrator can actually hold the system together.
For beginners, that is the real takeaway. Do not choose your orchestrator like you are picking a chatbot. Choose it like you are hiring the person who has to run the room. Right now, Kimi K2.5 looks like the safer hire. Qwen3.5:397B still looks like an intriguing specialist for the lab.
That is the difference between a cool demo and a system you can trust.
Get More Articles Like This
Getting your AI agent setup right is just the start. I'm documenting every mistake, fix, and lesson learned as I build PhantomByte.
Subscribe to receive updates when we publish new content. No spam, just real lessons from the trenches.